
기본
connect
SQL> connect system
Enter password:
Connected.system에 접속한다.
show user
SQL> show user
USER is "SYSTEM"
현재 접속하고있는 user를 확인한다.
잠금해제
ALTER USER HR ACCOUNT UNLOCK IDENTIFIED BY 1234;
SQL*PLUS
connect HR/1234@XE
Oracle에서 기본으로 제공되는 HR(Human Resources)에 잠금을 해제하여 사용자의 편의성을 높인다.
Schema 생성
다른 사용자 생성
CREATE USER "Test1" IDENTIFIED BY "1234"
DEFAULT TABLESPACE "USERS"
TEMPORARY TABLESPACE "TEMP";
권한 부여
GRANT "DBA" TO "Test1" ;
GRANT "CONNECT" TO "Test1" ;
GRANT "RESOURCE" TO "Test1" ;
새로운 스키마 접속
connect (스키마);
password :
Connected.
Table 생성
create table (tablename)(
COUMN_NAME DATA_TYPE NULLABLE primary key(기본키),
Foreign Key(외래키)
);
Data 입력
INSERT INTO (tablename) values(date type);
commit
commit;
항상 커밋을 해줘야 데이터가 저장된다.
SQL SELECT Code
SELECT
SELECT .. FROM .. WHERE
SELECT 열 이름 FROM 테이블 이름 WHERE 조건
SELECT * FROM memberTBL 멤버테이블의 모든 열을 보여D줘라.
SELECT .. FROM .. WHERE 관계연산자
SELECT 열 이름 FROM 테이블 이름 WHERE 조건(EX : year >= 10)
year이 10 이상인 데이터만 조회
INNER JOIN
조인이란 두 개 이상의 테이블을 서로 묶어서 하나의 결과 집합으로 만들어 내는 것을 말한다.
DB의 테이블은 중복과 공간 낭비를 피하고 데이터의 무결성을 위해서 여러 개의 테이블로 분리하여 저장한다.
그리고, 이 분리된 테이블 들은 서로 관계를 맺고 있다.
SELECT <열 목록>
FROM <첫 번째 테이블>
INNER JOIN <두 번째 테이블>
ON <조인될 조건>
WHERE <검색 조건>
---세 개 테블의 조인
SELECT <열 목록>
FROM <첫 번째 테이블>
INNER JOIN <두 번째 테이블>
ON <조인될 조건>
FROM <두 번째 테이블>
INNER JOIN <세번째 테이블>
ON <조인될 조건>
WHERE <검색 조건>
AND
SELECT 열 이름 FROM 테이블 이름 WHERE 조건 >= 10 and 조건 >= 15
10~15 를 조회
BETWEEN
SELECT 열 이름 FROM 테이블 이름 WHERE 조건 BETWEEN 10 and 15
10~15 를 조회
OR
SELECT 열 이름 FROM 테이블 이름 WHERE 조건
(EX : name='김' OR name='최' OR name='이')
김, 최, 이 를 조회한다.
IN
SELECT 열 이름 FROM 테이블 이름 WHERE 조건 IN('김', '최', '이')
연속적인 값이 아닌 이산적인 값을 위해 IN()을 사용한다.
LIKE
SELECT 열 이름 FROM 테이블 이름 WHERE 조건 LIKE '김%'
SELECT 열 이름 FROM 테이블 이름 WHERE 조건 LIKE '_길동'
SELECT 열 이름 FROM 테이블 이름 WHERE 조건 LIKE '_용%'
문자열 내용을 검색하기 위해서는 LIKE 연산자를 사용한다.
’김%’ 김이 제일 앞글자인것들을 추출한다. 또한 한글자와 매치하기 위해서는 ‘ _ ’를 사용한다. ’ _ ’ 와 ‘ % ’를 조합해서 사용할수도 있다. ’_용%’ 앞에 아무거나 한글자가 오고 두번째는 ‘용’, 그리고 세번째 이후에는 몇글자든 아무거나 오는 값을 추출해준다.
SubQuery
--name 최 age 17 addr 강원
--name 박 age 18 addr 강원
--name 김 age 15 addr 대구
--name 이 age 13 addr 서울
SELECT 열 이름 FROM 테이블 이름 WHERE 조건(EX : age > 15)
-- 김 추출
--SubQuery
SELECT 열 이름 FROM 테이블 이름 WHERE age > (
SELECT age FROM 테이블 이름 WHERE name = '김')
‘김’ 보다 age가 크거나 같은 사람의 열 이름을 출력하려면 ‘김’의 키를 직접 써줘야한다 하지만 age 15 를 쿼리를 통해 사용하는 것이다 뒷쪽의 (SELECT age FROM 테이블 이름 WHERE name = '김') 은 15 라는 값을 돌려주므로 결국 15와 값과 동일한 값이 되어서 위 두 쿼리는 동일한 결과가 나온다.
ANY
--name 장 age 20 addr 북한
--name 서 age 19 addr 부산
--name 최 age 17 addr 강원
--name 박 age 18 addr 강원
--name 김 age 15 addr 대구
--name 이 age 17 addr 서울
--첫번째 쿼리
SELECT 열 이름 FROM 테이블 이름 WHERE age >=
(SELECT age FROM 테이블 이름 WHERE addr = '강원')
--두번째 쿼리
SELECT 열 이름 FROM 테이블 이름 WHERE age >=
ANY (SELECT age FROM 테이블 이름 WHERE addr = '강원')
첫번째 쿼리를 실행하면 오류가 나온다 이유는 17, 18 이라는 두개의 값을 반환하기 떄문이다 그렇기 때문에 두번째 쿼리 처럼 ANY를 사용한다. 그러면 17보다 크거나 같은 값, 18보다 크거나 같은값이 모두 추출된다. ANY는 서브쿼리의 여러 개의 결과중에 한가지만 만족해도 된다. SOME = ANY ANY = IN
ALL
--name 장 age 20 addr 북한
--name 서 age 19 addr 부산
--name 최 age 17 addr 강원
--name 박 age 18 addr 강원
--name 김 age 15 addr 대구
--name 이 age 17 addr 서울
SELECT 열 이름 FROM 테이블 이름 WHERE age >=
(SELECT age FROM 테이블 이름 WHERE addr = '강원')
--두번째 쿼리
SELECT 열 이름 FROM 테이블 이름 WHERE age >=
ALL (SELECT age FROM 테이블 이름 WHERE addr = '강원')
ALL을 실행하면 17보다 크거나 같아야 할 뿐만 아니라 18보다 크거나 같아야 하기 때문에 18보다 크거나 같은 사람만 추출된다. ALL은 서브쿼리의 여러 개의 결과를 모두 만족시켜야 한다.
DROP TABLE
DROP TABLE (table name);
DROP을 통해 테이블을 삭제할수 있다. 대소문자를 구분하여야 한다.
COUNT()
SELECT COUNT(*) FROM tablename;
행의 개수를 알려주는 함수이다.
UPDATE
UPDATE tablename SET tablepasswrod = "1234"
WHERE tablepasswrod = "아이디1"
테이블 안에 있는 아이디1의 패스워드를 1234로 업데이트
DELETE
DELETE FROM tabelname WHERE tableid = '아이디1'
테이블안에 데이터를 삭제함.
삭제 데이터 백업
CREATE TABLE deletedTBL(
ID char(8),
Name nchar(5),
Address nvarchar2(20),
deletedDate date -- 삭제한 날짜
);
지워진 데이터를 보관한 테이블을 생성
CREATE TRIGER trg__deletedTBL --트리거 이름
AFTER DLELTE --삭제 후에 작동하게 지정
ON tablename --트리거를 부착할 테이블
FOR EACH ROW --각 행마다 적용됨
BEGIN
--:old 테이블의 내용을 백업 테이블에 삽입
INSERT INTO deletedTBL
VALUES (:old.name, :old.addr SYSDATE());
END;
삭제한 데이터를 deletedTBL에 저장함
DELETE FROM tabelname WHERE tableid = '아이디1'
테이블 안에있는 아이디1 을 삭제 tablename이랑 deletedTBL을 연결하여 삭제했을때 deletedTBL로 들어가 백업된다.
ORDER BY Code
결과물에 영향을 미치지는 않지만, 결과가 출력되는 순서를 조절하는 구문이다.
ORDER BY
SELECT 열 이름 FROM 테이블 이름 ORDER BY 열 이름
기본적으로 오름 차순으로 정렬된다.
DESC(내림차순), ASC(오름차순)
SELECT 열 이름 FROM 테이블 이름 ORDER BY 열 이름1 DESC,
열 이름2 ASC
열 이름1 은 내림차순, 열 이름2 는 오름차순 ORDER BY절은
SELECT,
FROM,
WHERE,
GROUP BY,
HAVING,
ORDER BY
중 가장 뒤에 와야한다.
DISTINCT
중복제거
--TESTTBL
--name 장 age 20 addr 부산
--name 서 age 19 addr 부산
--name 최 age 17 addr 강원
--name 박 age 18 addr 강원
--name 김 age 15 addr 대구
--name 이 age 17 addr 서울
SELECT DISTINCT addr FROM TESTTBL;
부산, 강원, 대구, 서울 만 출력 된다.
ROWNUM
--TESTTBL
--name 장 age 20 addr 부산
--name 서 age 19 addr 부산
--name 최 age 17 addr 강원
--name 박 age 18 addr 강원
--name 김 age 15 addr 대구
--name 이 age 17 addr 서울
SELECT name, age, addr FROM TESTTBL
WHERE ROWNUM <= 5
--name 장 age 20 addr 부산
--name 서 age 19 addr 부산
--name 최 age 17 addr 강원
--name 박 age 18 addr 강원
--name 김 age 15 addr 대구
ROWNUM을 사용하면 원하는 개수만큼 출력이 된다.
SAMPLE(퍼센트)
SELECT 열 이름 FROM 테이블 이름 SAMPLE(20)
테이블에 담긴 SAMPLE(20) 20퍼 만큼의 데이터를 가지고 온다.
CREATE TABLE ~ AS SELECT
--테이블 복사
CREATE TABLE 새로운 테이블 AS (SELECT 복사할 열 FROM 기존테이블)
--지정한 일부 데이터 복사
CREATE TABLE 새로운 테이블 AS (SELECT 복사할 열1, 복사할 열 2
FROM 기존테이블)
새로운 테이블에 기존 테이블에 데이터를 복사할수 있다. 필요하다면 지정한 일부 열만 복사할수도 있다.
GROUP BY, HAVING, 집계 함수
GROUP BY
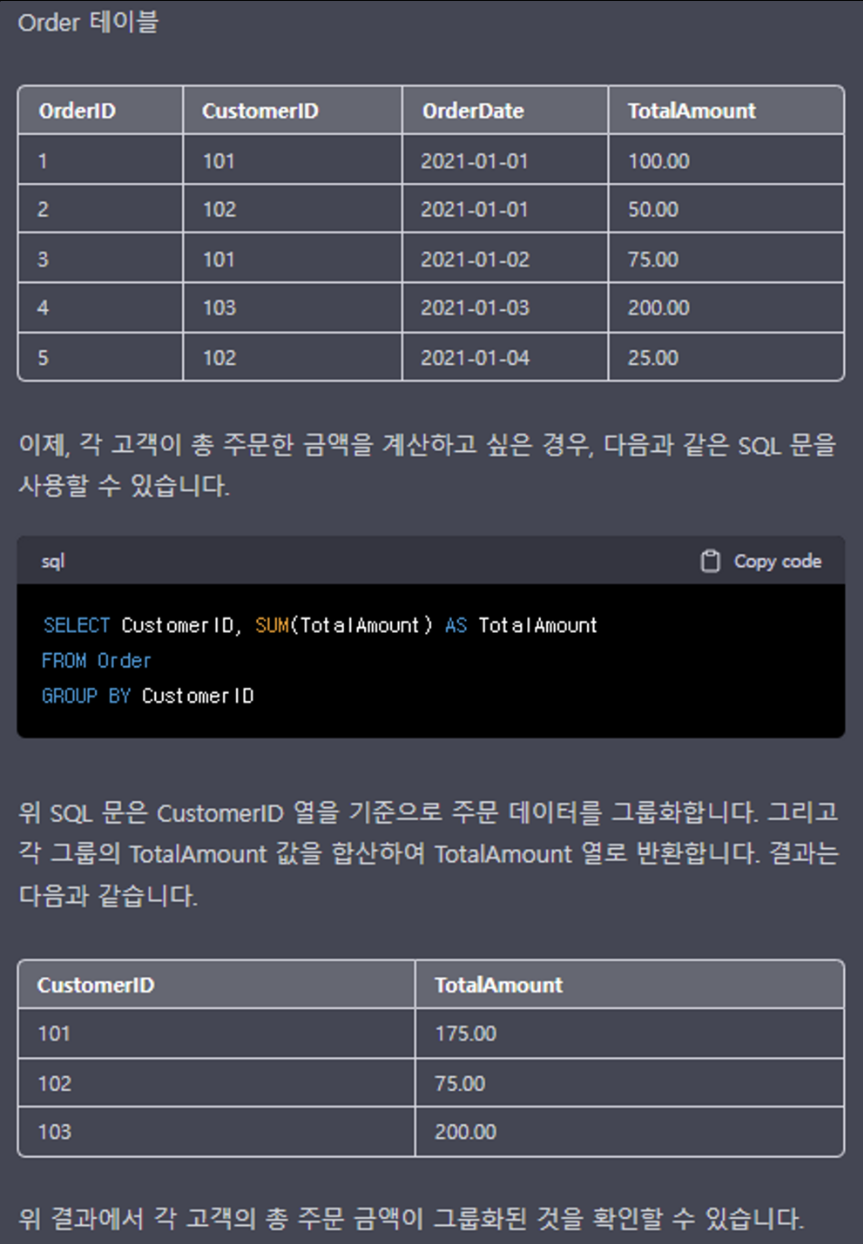
SQL의 GROUP BY 절은 SELECT 문에서 집계 함수와 함께 사용되며, 결과를 그룹화하는 역할을 합니다.
GROUP BY 절은 특정 열(또는 열의 집합)을 기준으로 결과 집합을 그룹화하고, 각 그룹에 대해 하나 이상의 집계 함수를 적용합니다.
예를 들어, 고객 주문 데이터에서 각 고객이 총 주문한 금액을 계산하고 싶다면, 고객 ID 열을 기준으로 GROUP BY를 사용하여 고객별 주문 금액을 계산할 수 있습니다.
HAVING
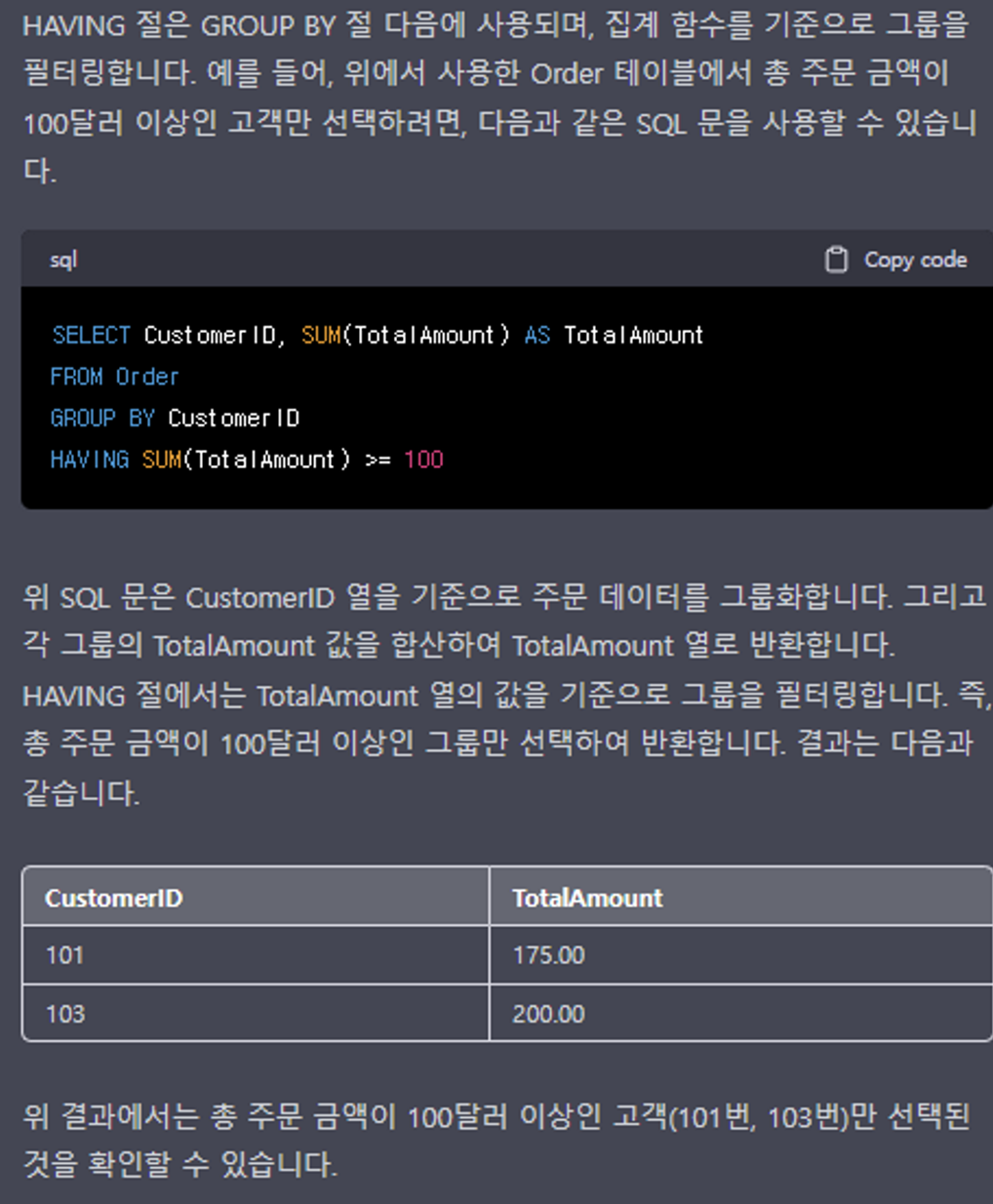
집계 함수
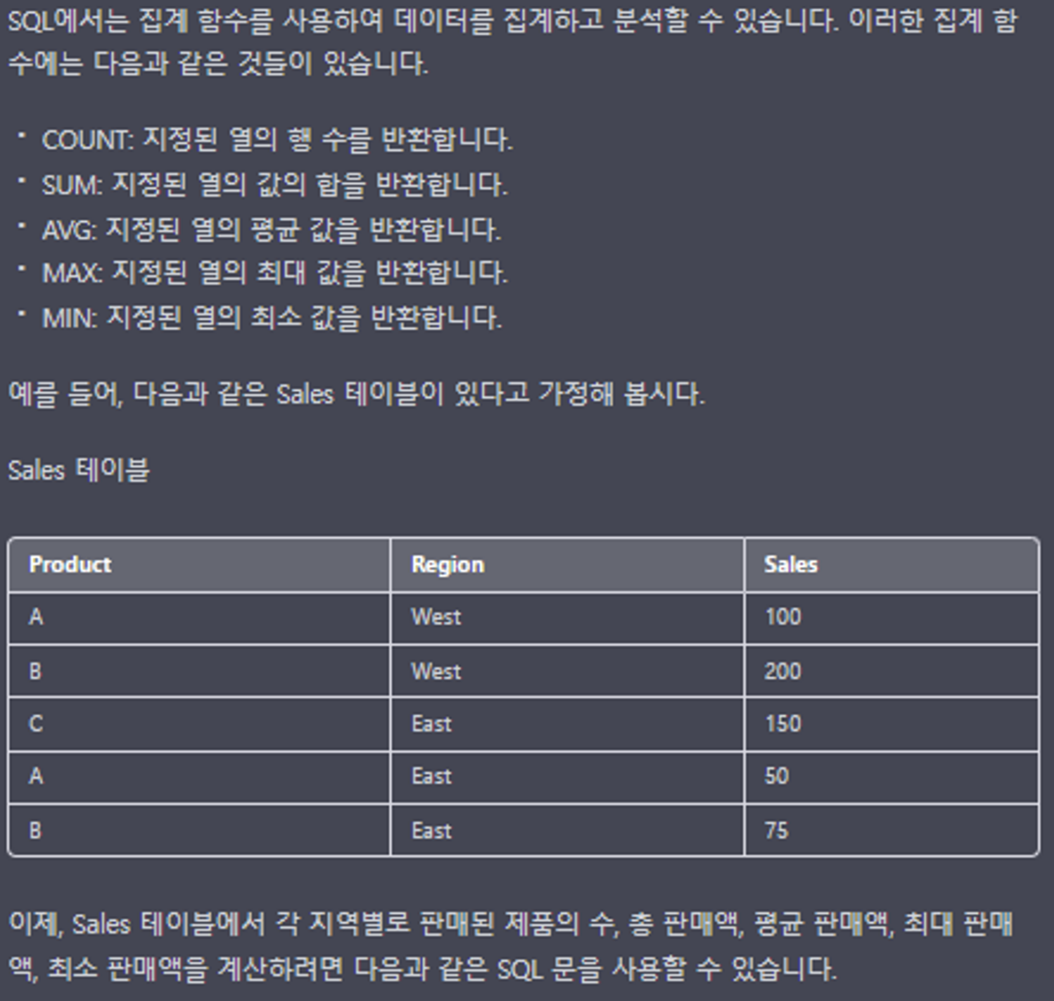
SELECT Region, COUNT(Product)
AS Count, SUM(Sales)
AS TotalSales, AVG(Sales)
AS AverageSales, MAX(Sales)
AS MaxSales, MIN(Sales)
AS MinSales
FROM Sales
GROUP BY Region

ROLLUP()
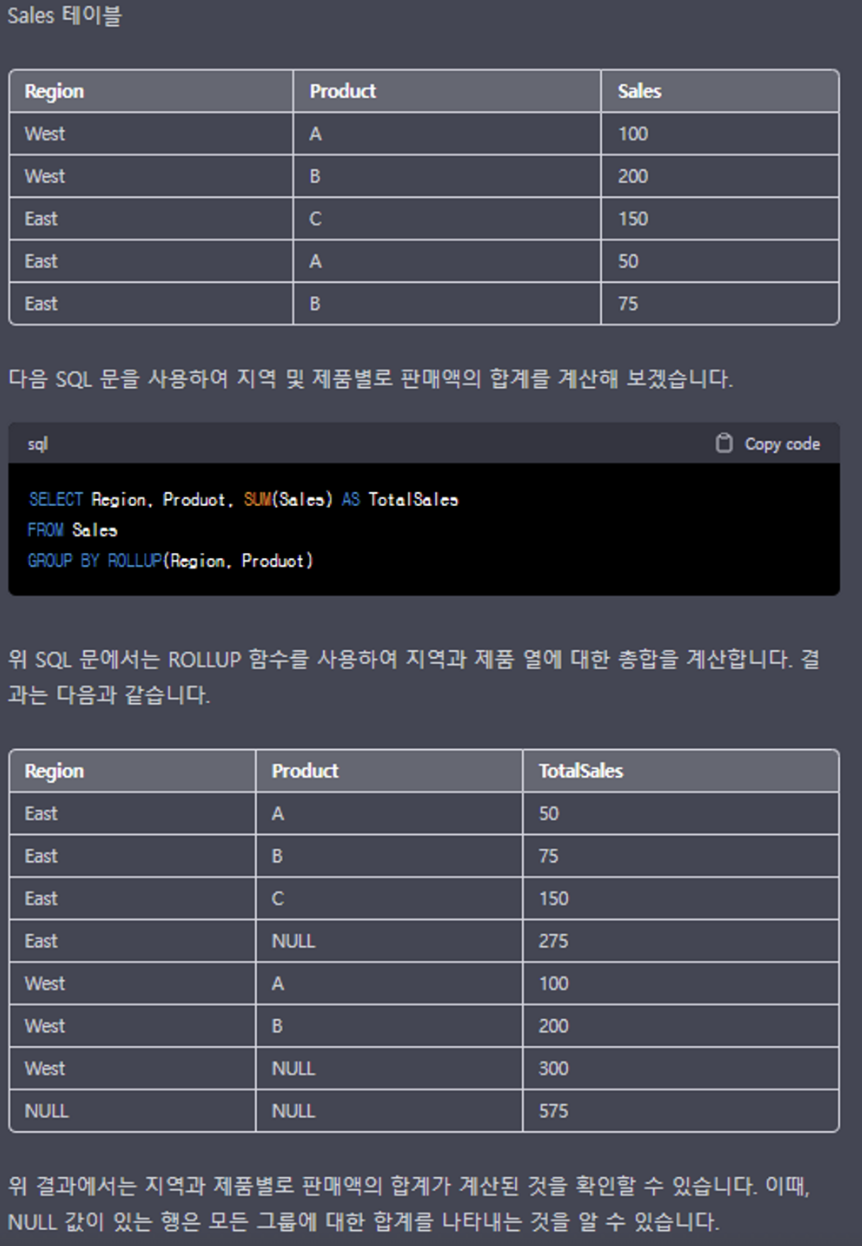
SQL에서 ROLLUP() 함수는 GROUP BY 절에서 그룹화된 데이터에 대한 계층적 요약을 제공하는 데 사용됩니다. ROLLUP() 함수는 지정된 열의 값에 따라 그룹화된 결과 집합의 계층적 합계 및 서브합계를 생성한다.
CUBE()
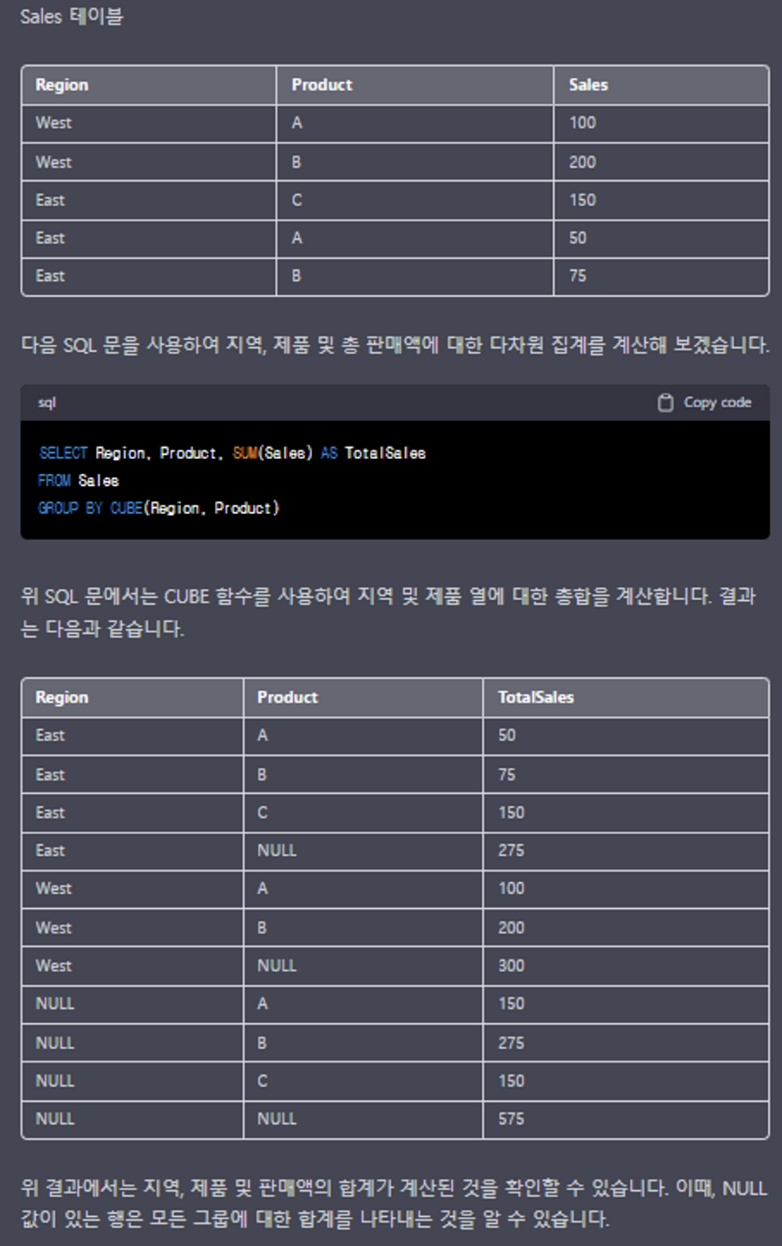
SQL에서 CUBE() 함수는 GROUP BY 절에서 그룹화된 데이터에 대한 다차원 요약을 제공하는 데 사용됩니다.
CUBE() 함수는 GROUP BY 절에서 지정된 열의 모든 가능한 조합에 대한 합계와 서브합계를 생성합니다.
WITH절과 CTE
WITH절은 CTE를 표현하기 위한 구문이다.
CTE는 기존의 뷰, 파생 테이블, 임세테이블 등으로 사용되던 것을 대신할수 있고 더 간결하게 사용하기위해 쓴다.
비재귀적 CTE
비재귀적 CTE는 복잡한 쿼리 문장을 단순화 시키는데 적합하게 사용할수 있다.
WITH CTE_테이블이름(열 이름)
AS
(
<쿼리문>
)
SELECT 열 이름 FROM CTE_테이블이름;
------------------------------------
//예시
SELECT userID AS "사용자", SUM(price*amount) AS "총구매액"
FROM buyTBL GROUP BY userID;
SELECT * FROM abc ORDER BY "총구매액" DESC;
WITH abc(userID, total)
AS
(
SELECT userID, SUM(price*amount)
FROM buyTBL GROUP BY userID
)
SELECT * FROM abc ORDER BY total DESC;
//abc는 실존하는 테이블이 아니라 WITH 구문으로 만든 SELECT의 결과이다.
비재귀적 CTE 쿼리 작성순서
1단계 → ‘각 지역별로 가장 큰 키’를 뽑는 쿼리는 다음과 같다.
SELECT addr, MAX(height) FROM userTBL GROUP BY addr
2단계 → 위의 쿼리를 WITH 구문으로 묶는다.
WITH cte_테이블이름(addr, maxHeight)
AS
(
SELECT addr, MAX(height) FROM userTbl GROUP BY addr
)
3단계 → ‘키의 평균’을 구하는 쿼리를 작성한다.
SELECT AVG(키) FROM cte_테이블이름
4단계 → 2단계와 3단계 쿼리를 합한다.
WITH cte_userTbl(addr, maxHeight)
AS
(
SELECT addr, MAX(height) FROM userTbl GROUP BY addr
)
SELECT AVG(maxHeight) AS "각 지역별 최고키 평균" FROM userTbl;
CTE는 중복 CTE가 가능하다.
WITH
AAA(컬럼)
AS("AAA"의 쿼리문),
BBB(컬럼)
AS("BBB"의 쿼리문),
CCC(컬럼)
AS("CCC"의 쿼리문)
SELECT * FROM [AAA 또는 BBB 또는 CCC]
CCC의 쿼리문에서는 AAA나 BBB를 참조할수 없다. AAA의 쿼리문이나 BBB의 쿼리문에서는 CCC를 참조할수 있다.
재귀적 CTE
쿼리를 반복적으로 호출한다.
WITH CTE_테이블이름(열 이름)
AS
(
<쿼리문1 : SELECT * FROM 테이블A>
UNION ALL
<쿼리문2 : SELECT * FROM 테이블A JOIN CTE_테이블이름>
)
SELECT * FROM CTE_테이블이름;
<쿼리문1> 을 앵커 멤버라고 부르고, <쿼리문2>를 재귀 멤버 라고 지칭한다. 작동 원리는
- <쿼리문1>을 실행한다. 이것이 전체 흐름의 최초 호출에 해당한다. 그리고 레벨의 시작은 0 으로 초기화 된다.
- <쿼리문2>를 실행한다. 레벨을 레벨+1로 증가시킨다. 그런데 SELECT의 결과가 빈 것이 아니라면, “CTE_테이블이름”을 다시 재귀적으로 호출한다.
- 계속 2번을 반복한다. 단, SELECT 의 결과가 아무것도 없으면 재귀적인 호출이 중단된다.
- 외부의 SELECT문을 실행해서 앞 단계에서의 누적된 결과 를 가져온다.
'SQL' 카테고리의 다른 글
| [SQL] INSERT (0) | 2023.07.19 |
|---|